
Decoding skin cancer classification: perspectives, insights, and advances through researchers’ lens

In this section, we discuss in detail the various strategies based on computer vision that have been employed to classify skin cancer found within the literature. The taxonomy of the different strategies is shown in Fig. 4.

Taxonomy of different skin cancer classification strategies used in this survey.
Machine learning-based techniques
Classification of skin cancer can be considered a supervised learning problem which can be tackled using ML-based systems. Such systems traditionally rely on handcrafted features. These features are meticulously designed through image processing and feature engineering methods, capturing specific characteristics and patterns within skin lesions that signify different types of skin cancer. These manually crafted features are then input into diverse classifiers, including SVMs, random forests (RFs), k-nearest neighbors (k-NNs), or artificial neural networks (ANNs), facilitating the classification of skin cancer. Importantly, the process of extracting handcrafted features is less computationally demanding compared to training deep neural networks, rendering these techniques more adaptable to resource-constrained environments39. Nevertheless, a significant drawback of such systems is their dependence on the quality of manually crafted features and their generalizability across diverse datasets.
Traditional ML models often allow for greater interpretability, enabling clinicians to understand the reasoning behind predictions. This interpretability is crucial in clinical settings, as it fosters trust and facilitates informed decision-making based on model outputs. However, this interpretability comes at a cost. While traditional models like DTs offer clear insights into how predictions are made, they often struggle to capture the complex relationships inherent in the data, resulting in lower predictive performance compared to more sophisticated models, such as DL approaches. In contrast, DL models, although typically yielding higher accuracy, operate as “black boxes”, making it difficult to decipher the underlying rationale for their predictions. This lack of transparency can be problematic in medical contexts, where understanding the basis for a diagnosis is vital for patient care and compliance with ethical standards.
The challenge, therefore, lies in striking a balance between performance and interpretability. Clinicians may favor models that are easier to understand, even if they sacrifice some predictive power, while data scientists may lean towards models that offer higher accuracy but lack transparency. As highlighted in recent literature, addressing this trade-off is crucial for the successful integration of machine learning systems in healthcare, where both precision and trust are paramount. In this section, we offer an overview of the existing ML-based approaches outlined in the literature, summarizing their employed feature extraction techniques, classifiers, and performance outcomes across the datasets utilized.
Traditional machine learning classifier-based techniques
This segment delves into the different methodologies for skin cancer classification using handcrafted features in conjunction with ML classifiers. A comprehensive comparison of skin cancer classification methods using ML classifiers is discussed in Table 3.
Jørgensen et al.40 explored the collective utilization of various optical coherence tomography (OCT) features extracted from images of basal cell carcinoma and actinic keratosis. They evaluated the diagnostic accuracy of these combined features through an ML approach. The results of the ML analysis indicated that the use of a multitude of features led to an accuracy of 77%. Zortea et al.41 proposed a method aiming to capture local spatial information by utilizing local binary pattern histograms (LBPH)42 from the images. The extracted features underwent clustering through k-means clustering and were then input into an SVM for the classification of images as malignant or benign. Ballerini et al.43 introduced a skin cancer classification system that integrates both color and texture features. They employed a hierarchical k-NN classifier for the classification task. Color features were represented by the mean colors \(\\mu = (\mu R, \mu G, \mu B)\\) of the lesion along with their covariance matrices. Texture features were extracted from generalized co-occurrence matrices (GCM)44. From each GCM, they derived 12 texture features, including energy, contrast, correlation, entropy, homogeneity, inverse difference moment, cluster shade, cluster prominence, max probability, autocorrelation, dissimilarity, and variance.
Mhaske et al.45 employed the 2D wavelet technique46 to generate 96 features from the images. Subsequently, these features were utilized by an SVM to classify the images as either malignant or benign. Maurya et al.47 proposed a skin cancer classification system, employing the gray level co-occurrence matrix (GLCM)48 as a feature extraction technique. Initially, the RGB image underwent conversion into a grayscale image, serving as input for GLCM. The computation by GLCM focused on the frequency of specific gray levels reappearing at different positions in the image. Feature extraction via GLCM mapped probabilities of gray level co-occurrence at various angular positions, relying on spatial relationships between different pixel combinations. Features like autocorrelation, contrast, energy, entropy, and homogeneity were then extracted from the matrix. These features were subsequently fed into a multi-class SVM for the classification task.
Choudhury et al.49 introduced a method for classifying skin cancer images, employing a multilayer decomposition approach based on textural and color features. Initially, images underwent decomposition into a piecewise base layer and detail layer using the weighted least squares (WLS) framework for edge-preserving decomposition. From the enhanced layer, GLCM and histogram of oriented gradients (HOG)50 served as textural feature descriptors, while the color histogram51 obtained from the base or smoothened layer was considered as the color feature descriptor. These feature values were passed as input into a multiclass SVM and extreme learning machine (ELM) for classification. The achieved accuracy was 94.18% with SVM and 90.5% with ELM, respectively. Bareiro et al.52 introduced an automated system utilizing a set of handcrafted features and an ML classifier for the detection of benign and malignant skin cancer from dermoscopic images. The proposed system employed various feature extraction techniques, including the Otsu algorithm53, asymmetry, border, color, and diameter (ABCD) rules54, inpainting techniques55, median filter56, and contrast limited adaptive histogram equalization (CLAHE)57. The Otsu algorithm played a crucial role in automated image segmentation, facilitating the separation of the region of interest (ROI) from the background, specifically aiding in isolating the lesion area for subsequent analysis. The ABCD rules align with established clinical assessment guidelines for melanoma, potentially improving accuracy. Inpainting techniques and median filter were responsible for removing unwanted artifacts and noise from the images, while CLAHE was used to enhance the contrast of the images. The classification model utilized an SVM as the classifier. The evaluation of this model on a self-procured dataset, consisting of 104 dermoscopic images, resulted in a classification accuracy of 90.63%.
Waheed et al.58 proposed an effective ML model designed for the early diagnosis of skin cancer using dermoscopic images from patients. In this model, the feature extraction phase utilized the uniform HSV color space59 and the GLCM. For classification, an SVM was employed. The use of the HSV color space facilitated a focused analysis of color variations, crucial for identifying color-based characteristics associated with different skin lesions. GLCM was instrumental in understanding spatial relationships between pixel values, aiding in the extraction of texture features. The model underwent training and testing on 200 dermoscopic images from the PH2 dataset, achieving an impressive accuracy of 96% during experimentation and classification. The flowchart of this system is shown in Fig. 5a. Ozkan IA and Koklu60 presented an ML-based decision support system designed to assist doctors and radiologists. The feature extraction phase of this system utilized the ABCD rules-based technique, similar to Bareiro et al.’s work52. For classification, four different classifiers, namely ANN, SVM, k-NN, and DT, were employed. The system underwent evaluation on 200 dermoscopic images obtained from the PH2 dataset, achieving classification accuracies of 92.50%, 89.50%, 82%, and 90%, respectively, during experimentation.
Tan et al.61 proposed an automated ML system for skin cancer diagnosis using dermoscopic images. The model incorporated various feature extraction techniques, including gray-level run-length matrix (GLRLM) , ABCD rules, local binary patterns (LBP)42, and HOG, and used particle swarm optimization (PSO)62 for feature selection. The ABCD rules captured shape and color features, GLRLM focused on texture information, LBP captured local patterns, and HOG extracted gradient-based features. PSO optimized feature selection, enhancing the overall feature set. The integration of these diverse features aimed to provide a comprehensive representation of the underlying characteristics of skin lesions. These features were then combined with SVM and k-NN ensembles for classification. The model was evaluated on 1500 skin lesion images of patients taken from two datasets, PH2 and Dermofit, and produced classification accuracy of 97.79% and 97.54% under SVM and k-NN respectively.
Gautam et al.63 utilized LBP, uniform LBP64 and complete LBP (CLBP)65 as feature extraction methods. The features extracted from each of these methods were separately fed into DT, RF, SVM, and k-NN classifiers. The findings suggest that a combination of CLBP and RF yielded the best accuracy. Javaid et al.66 introduced a methodology that involved the integration of image processing and machine learning classifiers. The approach featured an innovative technique for contrast stretching of dermoscopic images, based on the mean values and standard deviation of pixels. Subsequently, the Otsu thresholding algorithm was employed to binarize the images. Then, features such as GLCM for texture identification, HOG for object identification, and color features were extracted from the images. Dimensionality reduction on the extracted features was carried out using principal component analysis (PCA)67. The feature vector underwent standardization and scaling. Prior to employing classifiers, a distinct wrapper method for feature selection was proposed. The effectiveness of the proposed approach was assessed on the ISIC 2016 dataset, achieving a maximum accuracy of 93.89% with the RF classifier.
Observations: Handcrafted features in skin cancer classification are typically categorized into color, shape, and texture features, each of which plays a crucial role in characterizing skin lesions. Color features, such as mean color values and color histograms, were employed by43 and49, respectively, to capture the distribution of colors in lesions. Shape features, which focus on geometrical aspects and lesion edges, were extracted using methods like the Otsu algorithm by52,63. Texture features, which analyze the spatial arrangement of pixel intensities, were explored through various techniques. For instance, GCM was used by43, GLCM was widely used by47,49,58,63, while the GLRLM and LBP were employed by61 and61,63, respectively. LBPH and HOG were used by41 and49,61,63, respectively. Additionally, wavelet transform techniques, which provide multi-resolution analysis, have been utilized by45. ML-based systems incorporating handcrafted features are easy to implement, more interpretable, computationally efficient and often require less data for training compared to deep learning methods. However, handcrafted features are manually designed based on prior knowledge, which might not fully capture the intricate patterns and representations present in skin lesions. The effectiveness of these techniques heavily depends on the quality of the manually engineered features. Designing relevant features requires domain expertise and might be challenging due to the variability in lesion appearances.
References40,41,43,45,52 use a self-procured dataset for testing, limiting their comparison with other studies. While45,52,58,60 yield high accuracies, their evaluation on smaller datasets raises concerns about their robustness for real-world scenarios. The absence of experimental results on larger datasets questions the generalizability of these models.47,63 uses a larger dataset to test their method. Nevertheless, their method fails to achieve high accuracy. In contrast, the improved accuracy over a relatively larger number of images demonstrated in49,61,66 indicates the effectiveness of the proposed schemes, surpassing other ML-based systems. This highlights their potential for robust skin cancer classification. However, it is important to note that computing features using a combination of multiple handcrafted feature extraction techniques like ABCD rules, GLCM, GLRLM, LBP, HOG etc. can lead to increased computational complexity. Therefore, the utilization of optimal feature selection techniques, as demonstrated in61,66, becomes essential.
Artificial neural network-based techniques
ANNs coupled with handcrafted features offer ease of implementation, interpretability, and computational efficiency. Skin cancer classification often involves complex patterns and non-linear relationships within imaging data. ANNs, with their inherent non-linearity, excel at automatically learning relevant features from raw pixel data. This is advantageous in skin cancer classification tasks where manual feature engineering techniques may not capture the diverse and subtle characteristics of lesions68. Additionally, ANNs have demonstrated strong generalization capabilities using large labelled datasets. In skin cancer classification, where diverse cases are encountered, ANNs can generalize well to new, unseen examples. A comprehensive comparison of skin cancer classification methods using ANNs is discussed in Table 4.
Ercal et al.69 investigated the efficacy of ANNs in analyzing tumor shape and relative tumor color to differentiate between benign and malignant skin lesions. The study involved the development and assessment of neural network models trained on color images of skin lesions to precisely classify them as malignant or benign, contributing to improved diagnostic accuracy in melanoma detection. Bayot et al.70 underscored the significance of identifying malignancy in individuals at risk of basal cell carcinoma through the integration of image processing techniques and ANNs. The image processing approach incorporated histogram equalization71 to enhance the contrast of the images. Lau et al.72 also employed histogram equalization to enhance the images, with the resulting enhanced grayscale image serving as the model input. They utilized the 2D wavelet decomposition technique to extract relevant cancer-related features from the images, avoiding dependence on clinical knowledge. These features were then passed as input into a backpropagation neural network comprising 3 layers, and an auto-associative neural network. The achieved accuracies were 89.90% and 80.80%, respectively. Mahmoud et al.73 conducted a study centred on automatically identifying melanoma through the utilization of wavelet74 and curvelet75 analyses. This led to the advancement of the exploration of sophisticated image analysis techniques combined with neural networks for more accurate and early identification of melanoma.
Jaleel et al.76 introduced an automated skin cancer diagnostic system utilizing an ANN based on backpropagation. The model they proposed utilized a 2D wavelet transform technique for feature extraction, allowing for the representation of both spatial and frequency information, enabling a more comprehensive analysis of texture and structural patterns in dermoscopy images. This system was designed to categorize all input images into two classes: cancerous and non-cancerous. Subsequently, Jaleel et al.77 also employed the GLCM technique for feature extraction and fed the extracted features into an ANN with backpropagation. Similar to the approach by Jaleel et al.77, Mabrouk et al.78 also utilized GLCM for extracting texture features. They extracted a total of 23 GLCM features, and, following Fisher’s scoring method79, 11 features were selected, which subsequently formed the input to an ANN. Masood et al.80 introduced an automated skin cancer diagnostic system based on ANNs. The study delved into the effectiveness of three ANN learning algorithms: Levenberg-Marquardt (LM)81, resilient backpropagation (RBP)82, and scaled conjugate gradient (SCG)83. The comparative analysis revealed that the LM algorithm achieved the highest specificity score at 95.10%. It was particularly efficient in classifying benign lesions. The LM algorithm is known for its fast convergence and it tends to perform well when dealing with small to medium-sized datasets, which is often the case in skin cancer classification tasks. Additionally, it was observed that increasing the number of epochs led to improved results with the SCG learning algorithm, achieving a sensitivity value of 92.60%.
Choudhari et al.84 proposed an ANN-based diagnostic system involving lesion isolation using a maximum entropy thresholding measure. Then they utilized GLCM to extract distinctive features from the segmented images. Subsequently, a feed-forward ANN classified the input images into either a malignant or benign stage of skin cancer, achieving an accuracy of 86.66%. Aswin et al.85 developed a novel skin cancer detection method that incorporated genetic algorithms (GA)86 and ANNs. Their model included hair removal as a preprocessing step, executed through the medical imaging software, DullRazor87. Additionally, the ROI was isolated using the Otsu thresholding method. Unique features of skin lesions were then extracted using the GLCM technique followed by optimal feature selection using GAs. Ultimately, the proposed model utilized an ANN to classify images into cancerous and non-cancerous categories and achieved an overall accuracy score of 92.30%. The structure of the hybrid GA-ANN classifier is shown in Fig. 5b. Xie et al.88 introduced a skin lesion classification system designed to categorize lesions primarily into malignant and benign classes. The system operated through three key stages. Initially, a self-generating neural network was employed for lesion extraction from images. Following this features related to tumor border, color, and texture details were extracted, totalling 57 features, with 7 novel features specifically focused on lesion borders. PCA was then applied for dimensionality reduction to identify the most optimal feature set. In the final stage, classification was carried out using an ensemble neural network model that combined backward propagation neural networks and fuzzy neural networks. The model’s classification performance was compared with other classifiers such as SVM, k-NN, RF, and AdaBoost. The proposed model exhibited approximately 7.50% higher sensitivity compared to alternative classifiers and achieved an impressive accuracy rate of 91.11%.
In the research conducted by Kanimozhi et al.89, the ABCD rules were employed for extracting features from lesion images. Their study focused on leveraging ANN with suitable backpropagation algorithms to assist in the accurate and automated detection of melanoma, contributing to improving diagnostic capabilities specifically for this type of skin cancer. The paper by Cueva et al.90 introduced a mole classification system designed for the early diagnosis of melanoma skin cancer. This system extracted features based on the ABCD rules of lesions, focusing on asymmetry, borders, color, and diameter of moles. Asymmetry was determined using the Mumford-Shah algorithm91, while the Harris–Stephens algorithm92 extracted mole borders. Moles with colors other than black, cinnamon, or brown were considered potential indicators of melanoma. Additionally, melanoma moles typically have a diameter exceeding 6 mm, which serves as a threshold for their detection. The proposed system utilized a feed-forward backpropagation ANN to classify moles into common mole, uncommon mole, or melanoma mole categories, achieving an accuracy of 97.51%.

(a) Flowchart of the skin cancer classification system proposed by Waheed et al.58; (b) Structure of the hybrid GA-ANN classifier proposed by Aswin et al.85.
Observations: Like ML classifier-based techniques, ANNs also utilize handcrafted features. GLCM was employed by77,78,84,85. Wavelet and curvelet techniques were used by72,76 and73, respectively. The Otsu algorithm was employed by85. While the combination of ANNs with handcrafted features has proven effective in capturing non-linear relationships within image features, these systems share many limitations with ML-based approaches. The manual choice and design of features can be a subjective process, varying among researchers. This subjectivity introduces bias and inconsistency in feature extraction, potentially reducing classification accuracy in real-world scenarios.
References69,70,72,73,76,77,78,80,84,85,88,89,90 all utilize proprietary datasets for testing their methods, limiting comparisons with other methods. While69,70,73,80 produce fairly decent results, they do not emphasize the creation of an effective set of image features for utilization by their ANN models. On the other hand, Refs.72,76,77,84,89,90 incorporate sophisticated image processing techniques to capture features but do not focus on optimal feature selection, potentially leading to computational inefficiency due to increased features. In contrast, Refs.85,88 employ GA and PCA-based techniques for feature selection and feature reduction, respectively, resulting in improved results. Mabrouk et al.78 also emphasizes the importance of optimal feature selection through the application of Fisher’s scoring technique. However, it is important to note that handcrafted features struggle to capture intricate and complex patterns present in skin lesions, especially when dealing with subtle or non-obvious visual cues. This limitation can impact the model’s capacity to accurately distinguish between malignant and benign lesions, and it becomes even more pronounced in the context of multi-class classification of skin cancer, despite careful feature selection.
Kohonen network-based techniques
Kohonen networks93 offer an alternative to ANNs and traditional ML classifiers when incorporating handcrafted features for classification tasks. Renowned for their ability to preserve the topology of input data, Kohonen networks prove advantageous in skin cancer classification by maintaining spatial relationships and structures within the feature space, potentially capturing essential contextual information. In contrast to ANNs and ML classifiers, Kohonen networks inherently perform dimensionality reduction as they map high-dimensional input data to a lower-dimensional grid. Moreover, these networks naturally cluster similar patterns together on the map, providing an intuitive means to visualize the distribution of different lesion types. This clustering feature aids in identifying distinct groups and patterns within the dataset. A comprehensive comparison of skin cancer classification methods utilizing Kohonen networks is discussed in Table 5.
In their research, Lenhardt et al.94 presented a skin cancer detection system centred around Kohonen networks. The study involved the utilization of synchronous fluorescence spectra from melanoma, nevus, and normal skin samples for training the network. To capture the fluorescence spectra of these samples, obtained from human patients immediately post-surgery, a fluorescence spectrophotometer was employed. The dimensionality of the measured spectra was reduced through PCA. Following this, both Kohonen networks and ANNs underwent training using this dataset. Kohonen networks demonstrated superior performance compared to ANNs, exhibiting lower classification errors. Mengistu et al.95 introduced a skin cancer detection system that integrated Kohonen networks and radial basis function (RBF) neural networks. The input for this system consisted of color information, along with features derived from GLCM analysis and morphological characteristics extracted from lesion images. The performance of the proposed system was then compared to other classifiers, including k-NN, ANN, and Naive Bayes classifier. The results showcased that the amalgamation of the Kohonen network and RBF neural network achieved an impressive accuracy of 93.15% and outperformed the other classifiers.
In their work, Sajid et al.96 introduced a skin cancer diagnostic system leveraging Kohonen networks. The authors implemented a median filter to efficiently eliminate noise from the images. For image segmentation, a region growing and merging algorithm97 was employed on the filtered images. The system utilized a combination of textual and statistical features for classification, with statistical features extracted from lesion images and textual features extracted from the curvelet domain. The primary goal was to categorize input images into malignant and benign classes. The proposed model demonstrated an exceptional accuracy of 98.30%. In evaluating the system’s performance, it was compared with other classifiers, including SVM, a backpropagation neural network, and a 3-layered neural network. The results indicated that SVM achieved an accuracy of 91.10%, the neural network with backpropagation reached 90.40% accuracy, and the 3-layered neural network attained 90.50% accuracy. Notably, these accuracies were considerably lower than the accuracy achieved by the proposed system.
Observations: While the ability of Kohonen networks to preserve intricate spatial relationships and perform feature reduction is advantageous for skin cancer classification, they also come with certain drawbacks. Their reliance on feature engineering and their inability to capture hierarchical relationships stand out as primary limitations98. Besides, unlike ANNs, Kohonen networks lack inherent support for end-to-end learning, limiting their adaptability to more complex data relationships.
References94,96 incorporate simplistic feature engineering methods for feature extraction and evaluate their models on self-procured datasets, limiting fair comparisons with other research. On the other hand, Mengistu and Alemayehu95 demonstrates high accuracy and superior performance of Kohonen networks over ANNs and traditional ML classifiers. Nevertheless, with the rise of deep CNNs, Kohonen networks have gradually lost their relevance.
Deep learning-based techniques
The emergence of DL, a specialized subset of ML, has yielded rapid growth in the fields of pattern learning, image classification and recognition. DL models are trained on input data and not programmed explicitly. After the training phase, these models act as experts in the domain in which they were trained. Deep neural networks play an important role in the classification of skin cancer. In this section, we discuss various types of DL techniques that have been trained to classify images and distinguish between different types of skin cancer. Figure 6a presents a pie chart illustrating the proportions of research papers based on various DL models. Notably, papers utilizing CNNs constitute over 70% of the surveyed literature.

(a) Pie chart illustrating the percentage distribution of papers based on different DL models. (b) Pie chart illustrating the percentage distribution of papers based on various CNN-based techniques.
Convolutional neural network-based techniques
In the field of medical imaging, CNNs have demonstrated exceptional performance in tasks involving detection, segmentation, and classification. For an in-depth understanding of CNNs’ automated feature extraction abilities, readers may refer to key studies in99. CNNs play a significant role in skin cancer classification due to their ability to automatically learn intricate patterns and features from images. Unlike traditional methods that rely on handcrafted features, these neural networks are adept at capturing hierarchical features within the numerous lesion images, recognizing patterns at various levels of abstraction100. Initially, CNNs detect simple features like edges and textures, and as the network deepens, they capture more complex structures, such as irregularities in symmetry, borders, textures, and other visual cues crucial for distinguishing between different types of skin lesions. By stacking convolutional and pooling layers, CNNs gradually refine their feature detection, allowing them to identify subtle differences in lesion appearance that might not be apparent to the naked eye. This ability enables more accurate diagnosis and can significantly assist dermatologists in identifying early signs of skin cancer. In this section, we present a comprehensive discussion of the several CNN-based methods extensively used for skin cancer classification. Figure 6b presents a pie chart illustrating the proportions of papers using various CNN-based techniques.
Conventional CNN-based techniques
This section outlines the various custom CNN architectures devised by researchers for skin cancer classification. Nasr-Esfahani et al.101 developed a CNN with the aim of enhancing the accuracy and efficiency of detecting melanoma through automated analysis of clinical images. The CNN consisted of 2 convolutional layers to capture patterns from the images, 2 max-pooling layers to reduce the size of the feature maps, a fully connected layer and a final output layer containing 2 neurons, representing the categories of malignant and benign. Sabouri et al.’s work102 involved the development and training of CNNs to accurately identify and outline lesion borders within medical imaging data. The main objective of this work was to improve the precision and automation of lesion border detection, contributing to enhanced medical image analysis techniques for diagnosing and understanding various medical conditions. Ali et al.103 developed LightNet, a CNN with fewer parameters and suitable for mobile applications. The study utilized a conventional CNN architecture featuring 5 convolutional layers, 3 max-pooling layers, and 2 fully connected layers. To limit the parameters, they maintained a moderate number of filters in the convolutional layers. Batch normalization was applied after each convolutional layer to expedite convergence and impose regularization. Additionally, dropout was implemented in the fully connected layers to mitigate overfitting.
Esteva et al.104 employed a combination of convolutional layers, pooling layers, Inception modules, and residual connections allowing the network to learn powerful features from skin lesion images and to achieve high accuracy in skin cancer classification. The Inception modules helped to combine convolutional filters in parallel for multi-scale feature extraction. Also, they used global average pooling instead of fully connected layers to reduce the network’s complexity and avoid overfitting. Ayan et al.105 designed a CNN comprising 11 layers and emphasized the significance of data augmentation for constructing a robust skin cancer classifier. They applied various image augmentation techniques, including random transformations, rotations at different angles, shifting, zooming, and flipping. The classifier achieved an accuracy of 78% on the original dataset and an accuracy of 81% on the augmented dataset. Mandache et al.106 developed a CNN with a series of convolutional layers with varying filter sizes and non-linear activation functions to extract relevant features from 40 full field OCT (FF-OCT) images. These features capture various aspects of the basal cell carcinoma morphology such as loss of normal skin layering, presence of cystic spaces and retraction of the epidermal-dermal junction.
Along with the conventional convolutional and pooling layers, Namozov et al.107 utilized a parameterized activation function called the adaptive piecewise linear unit (APLU). APLU consists of adjustable parameters which allows the model to learn more complex and nuanced decision boundaries, potentially leading to improved feature discrimination and classification accuracy. In a study conducted by Ahmed et al.108, a standard CNN featuring multiple convolutional and pooling layers was utilized to classify lesion images sourced from the ISIC archive. The researchers also conducted experiments with Naive Bayes, SVM, k-NN classifiers, with CNNs demonstrating superior performance. Mridha et al.109 introduced a customized CNN architecture comprising two blocks for the feature extraction phase. In block 1, there were 2 convolutional layers with a kernel size of 3, accompanied by a pooling layer with a stride of 1, and a dropout layer. Block 2 included two convolutional layers with a kernel size of 3, a pooling layer with a stride of 2, and a dropout layer. The output from block 2 was flattened and subsequently passed through a final dense layer.
SkinNet-8, designed by Fahad et al.110, is a relatively simple yet computationally efficient CNN with 10 layers, including 5 convolutional layers, 3 pooling layers, and 2 dense layers. All these layers have been organized into 3 blocks. The model begins with an input image of fixed size, processed through the first block, which consists of a single convolutional layer followed by a max-pooling layer. The output from the first block feeds into block two and block three, each composed of two convolutional layers and a max-pooling layer. The resulting feature maps from the last block are flattened into a 1D vector, which is connected to dense layers. Finally, a softmax activation function is utilized to perform binary classification. It achieved a remarkable test accuracy of 98.81% on the imbalanced ISIC 2020 dataset. Figure 7 shows the architecture of SkinNet-8. Rastegar et al.111 proposed a deep CNN with 69 layers, aiming to extract detailed and discriminative features from skin lesion images. The network consists of multiple convolutional layers with different filter sizes, \(3 \times 3\), \(5 \times 5\), \(7 \times 7\), and depths. The network also contains residual layers, Inception modules and pooling layers accompanied by a final fully connected classification layer. A comprehensive comparison of skin cancer classification methods using conventional CNNs is discussed in Table 6.

Architecture of the SkinNet-8 model proposed by Fahad et al.110.
Observations: While conventional CNNs have shown promise in skin cancer classification, they often operate with fixed-size convolutional filters, making it challenging to capture long-range dependencies or understand the global structure of large images. Additionally, the pooling layers employed in CNNs decrease the spatial resolution of feature maps, resulting in information loss. This decrease in spatial resolution might discard crucial fine-grained details necessary for precise skin cancer classification.
References101,102,106 make use of proprietary datasets for testing their CNN architectures, limiting comparative analysis with other models. While Ali and Al-Marzouqi103 might prove useful for mobile applications, it renders low accuracy due to less number of filters in the convolutional layers. Although Ayan and Ünver105 does not achieve high accuracy, attributed to the simplistic CNN architecture employed, it still demonstrates satisfactory results, emphasizing the crucial role of data augmentation in this domain. The integration of Inception modules into CNNs, as demonstrated by104, stands as a crucial advancement, adopted in subsequent research. Namozov and Im Cho107 yields good results on the challenging ISIC 2018 dataset. However, they do not consider the underrepresented class of benign keratosis. References108,110,111 produce impressive binary classification results through relatively simple architectures. Moreover, the study conducted in108 indicates the superior performance of DL-based CNN models over traditional ML classifiers. However, they do not evaluate their methods for multi-class classification scenarios. With a simple CNN architecture, Mridha et al.109 yields low accuracy for multi-class classification. This underscores the limitation of simple conventional CNNs in effectively classifying diverse categories of skin lesions.
Transfer learning-based techniques
Transfer learning (TL) plays a pivotal role in skin cancer classification by leveraging knowledge learned from pre-trained models on large, diverse datasets to improve the performance of models trained on smaller skin cancer datasets. This approach is particularly beneficial due to the limited availability of skin cancer-related data. TL also leads to faster training times112. However, it is important to recognize that pre-trained models are typically trained on datasets like ImageNet, which consists of everyday objects, scenes, and animals. In contrast, medical images, especially dermoscopic skin lesion images, are highly specialized and characterized by unique patterns, textures, and color variations that are tied to biological factors. This difference leads to a domain shift between natural and medical images, making it challenging for pre-trained models to generalize effectively. If this domain shift is not addressed, models trained on natural images may fail to capture essential diagnostic features in medical images, resulting in poor classification performance.
To mitigate this, fine-tuning the pre-trained models on skin lesion datasets is an effective strategy. By gradually updating the model’s weights, the model can adapt to the new domain while retaining useful knowledge from the original one. A common technique is to freeze the lower layers of the pre-trained model, responsible for capturing general features like edges and textures, and only fine-tune the higher layers that learn task-specific features. This approach helps prevent overfitting on the small medical dataset while enabling the model to better align with the new domain. A comparative analysis of various skin cancer classification methods based on TL is presented in Table 7.
A pre-trained deep CNN architecture, VGG16 with the last 3 fine-tuned layers and 5 convolutional blocks was proposed by Kalouche et al.113. For fine-tuning, they employed a stochastic gradient descent (SGD) optimizer with a low learning rate. This model built on VGG16 produced 78% accuracy for melanoma classification. De Vries and Ramachandram114 introduced a multi-scale CNN utilizing the InceptionV3 architecture. They fine-tuned the pre-trained InceptionV3 model on two distinct resolution scales of input lesion images: a coarse scale and a finer scale. The multi-scale network is established by initially processing both the low-resolution image and the high-resolution image using the same InceptionV3 feature extractor. The resulting feature vectors from each image are combined to form a singular 4096 element vector. This combined vector then undergoes processing through a fully connected layer. Ultimately, a three-way softmax function is applied to generate probability predictions for the three classes: melanoma, seborrheic keratosis, and nevus.
Like Kalouche et al.’s approach113, Lopez et al.115 proposed a deep CNN built on the VGG16 architecture. This pre-trained model was then fine-tuned by replacing the last 2 fully connected layers with new layers specific to the binary classification task. Additionally, they replaced the activation function in the modified layer from softmax to sigmoidal. Mendes and da Silva116 proposed a deep CNN architecture based on pre-trained ResNet152 to classify 12 different kinds of skin lesions. Initially, the proposed model was trained on 3797 lesion images collected from the MED-NODE, Dermofit, and AtlasDerm datasets. Later, 29 times augmentation was applied depending on lighting positions and scale transformations. Hosny et al.117 utilized the pre-trained AlexNet architecture for feature extraction while developing their classification model. Here, the first few layers of AlexNet are kept frozen (not further trained), while the last layers are replaced with a new softmax layer. This new layer combines the extracted features to classify melanoma, common nevus and atypical nevus lesions.
Rezvantalab et al.118 employed 4 deep CNNs, namely, InceptionV3, InceptionResNetV2, ResNet152, and DenseNet201. Each network underwent fine-tuning across all layers, with the top layers replaced by a global average pooling layer and a softmax layer. DenseNet201 demonstrated superior performance with an AUC score of 0.979. The study also compared these networks’ performance with highly trained dermatologists, revealing that the networks outperformed dermatologists by at least 11%. Emara et al.119 employed the InceptionV4 backbone and introduced modifications by incorporating feature reuse through a residual connection. This connection played a crucial role in merging features extracted from earlier layers with those from high-level layers, contributing to an enhancement in the classification performance of the model on the challenging ISIC 2018 dataset. Gulati et al.120 explored two ways of using pre-trained models. Similar to Hosny et al.’s work117, they used fine-tuned AlexNet. They also used VGG16 as a feature extractor. Here, instead of fine-tuning, the features extracted by the layers of VGG16 are fed into a new fully connected layer trained specifically for melanoma classification. The modified VGG16 network outperformed AlexNet and achieved an accuracy of 97.50% on the PH2 dataset.
Le et al.121 utilized the ResNet50 backbone with additional modifications for the classification of 7 types of skin cancer. Their adaptations included the use of global average pooling instead of simple average pooling and the introduction of a dropout layer between the last 2 fully connected layers. Furthermore, they used a combination of weighted loss and focal loss to optimize their model. Sagar et al.122 employed several pre-trained models for the binary classification of melanoma. They performed experiments using InceptionV3, InceptionResNetV2, ResNet50, MobileNet and DenseNet169, out of which ResNet50 emerged with superior performance. Shen et al.123 leveraged a low cost and high performance data augmentation strategy along with TL for automatic skin cancer screening in rural communities. Their network, built on EfficientNetB7 architecture, achieved a multi-class classification accuracy of 85.30% on the HAM10000 dataset. Naeem et al.124 proposed an architecture based on the VGG16 model, enhancing its depth by adding two additional convolutional blocks. This modification was aimed at enabling the network to learn fine-grained features more effectively, thereby improving its capacity for detailed feature extraction for skin cancer classification.
Observations: While TL significantly contributes to skin cancer classification by harnessing the knowledge acquired from pre-trained models, sometimes, these pre-trained models might have been trained on datasets that do not align perfectly with the target task or have different classes. In such cases, pre-trained models might not adapt well to these differences and the relevance of the pre-trained features to the skin cancer classification task might be limited. Therefore, it becomes crucial to fine-tune the model appropriately. Inadequate fine-tuning choices could lead to a model that struggles to generalize effectively to the target dataset.
While emphasizing the significance of data augmentation, Mendes and da Silva116 does not assess their network’s performance on larger datasets, giving rise to concerns regarding its generalizability. Although Refs.117,120 achieve impressive results on the small PH2 dataset, like116, their networks are not tested on larger datasets, restricting broader evaluation. References113,122,124 demonstrate promising outcomes, but they evaluate their models on a subset of images rather than the entire dataset, making direct comparisons challenging. Although Refs.113,115 use the same network, Lopez et al.115 yields enhanced results over Kalouche et al.113 demonstrating the importance of suitable fine-tuning. The study conducted in118 demonstrates that TL-based networks surpassed dermatologists in achieving precise classification, thereby underscoring the significance of incorporating such models in a clinical setting. While Emara et al.119 presents a new perspective by introducing a modified Inception architecture along with residual connections, it is noteworthy that the sensitivity score of their model is relatively low. This poses a significant limitation, as misclassifying an individual with cancer as not having the condition carries a higher risk than the opposite scenario. Le et al.121 introduces a hybrid loss approach to tackle class imbalance. However, like Emara et al.119, the sensitivity score of their model is also observed to be low. DeVries and Ramachandram114 introduces an innovative multi-scale network that not only delivers impressive outcomes but also opens new pathways for models using feature fusion. The underwhelming multi-class classification outcomes observed on the challenging HAM10000 dataset in123 underscore the necessity for more effective strategies beyond vanilla TL-based approaches.
Attention-based techniques
Incorporating attention mechanisms within CNNs for skin cancer classification enhances models’ ability to concentrate on crucial features within the skin lesions by assigning weights to the feature maps according to their relevance to the lesions. This integration also helps suppress image artifacts, like portions of uninfected skin, hair, and veins, contributing to more accurate and precise diagnostic outcomes. A comparative analysis of various skin cancer classification methods based on attention mechanisms is presented in Table 8.
Zhang et al.125 proposed an attention residual learning CNN (ARL-CNN) model for the classification of skin lesions. This model comprised multiple ARL blocks, a global average pooling layer, and a classification layer. Each ARL block employed both residual learning and a unique attention learning mechanism to improve its capacity for capturing discriminative representations. The attention learning mechanism, rather than introducing extra learnable layers, aimed to leverage the inherent self-attention ability of deep CNNs. Specifically, it utilized feature maps learned by a higher layer to generate the attention map for a lower layer. Wu et al.126 introduced the ARDT-DenseNet, a densely connected convolutional network with attention and residual learning, for skin lesion classification. The ARDT block comprised dense blocks, transition blocks, and attention and residual modules. In comparison to a residual network with an equivalent number of convolutional layers, the parameter size of the proposed densely connected network was halved. The enhanced densely connected network incorporated an attention mechanism and residual learning after each dense block and transition block, providing additional functionality without introducing extra parameters.
Xue et al.127 introduced a novel network designed to differentiate between visually similar skin lesions, a challenging task for conventional neural networks. They utilized ResNet50 as the backbone network for extracting features from dermoscopic images. In addition to this, they developed a novel distinct region proposal module (DRPM), which is enhanced by the sequential computation of channel and spatial attention mechanisms. These attention mechanisms are crucial for focusing on critical areas within the lesions, allowing the model to identify and extract features from distinct regions that are particularly indicative of specific lesion types. Features extracted from these regions are then combined with those previously derived from the original dermoscopic images. This concatenated feature set forms the comprehensive input for the final classification task, aiming to accurately categorize skin lesions based on their subtle differences.
Ding et al.128 proposed the Deep Attention Branch Network (DABN) model, incorporating attention branches to enhance traditional deep CNNs. In the training stage, the attention branch was crafted to acquire the class activation maps, subsequently serving as attention maps directing the network’s focus to discriminative regions in skin lesions. DABN demonstrated applicability across diverse deep CNN structures and underwent end-to-end training. The DABN model incorporated 2 attention branches into the baseline architecture, which consisted of 4 dense blocks, 3 transition layers, and a classification layer. The dense block utilized the outputs of all preceding layers as input for each layer, promoting feature reuse and including multiple \(1 \times 1\) and \(3 \times 3\) convolutional layers. The transition layer incorporated a \(1 \times 1\) convolutional layer and \(2 \times 2\) average pooling to reduce the channel and size of the feature map. Finally, the classification layer employed global average pooling and 2 fully connected layers to generate the probability score for each category.
Following Xu et al.’s work129, Datta et al.130 proposed a skin cancer classification model using InceptionResNetV2 as backbone, aided with a soft attention unit. Here, the soft attention unit consists of two phases, a bilinear attention layer and a step to compute the weighted feature maps. Based on Eq. (1), the weighted feature maps are calculated by passing the feature tensor \(t \in \mathbb R^h\times w\times d\) to a 3D convolution layer with weights \(W_k \in \mathbb R^h\times w\times d \times K\), where K represents the number of 3D weights. Following this, a softmax function is applied to normalize each of the K attention maps. These normalized maps are then aggregated to create a composite attention map, which acts as a weighting function denoted as \(\alpha\). This \(\alpha\) value is used to scale the input tensor t, further adjusted by a trainable scalar \(\gamma\). Ultimately, the scaled attentive features \(f_sa\) are combined with the input tensor t. Figure 8 depicts the overview of this soft attention unit.
$$\beginaligned f_s a=\gamma t \left( \left( \sum _k=1^Ksoftmax(W_k*t)\right) \right) \endaligned$$
(1)
Similar to Datta et al.’s work130, Alhudhaif et al.131 proposed an attention module, where they analyzed the feature maps and assigned weights based on their relevance to the lesion, highlighting important areas for further processing. They built their classification model by first employing two convolutional layers to extract basic features from the input images. Then, they added their attention block followed by four more convolutional layers. Finally, they used a multi-class prediction layer to obtain the output probabilities. They were able to achieve an impressive accuracy of 95.90% on the challenging HAM10000 dataset.
Roy et al.132 used the wavelet transform technique, a soft attention module, and their novel Symmetry-aware Feature Attention (SaFA) module for skin cancer classification. The SaFA module was designed to extract symmetry-related information from the lesions and detect semantic variations. This module consists of two key components: the Feature Difference-aware Block (FDaB) and the Symmetry-aware Block (SaB). The FDaB processes an input feature map with dimensions \(H \times W \times C\) and reduces it to \(H \times W \times 1\) using three separable convolution layers. The resulting feature map is reshaped into two feature maps of dimensions \(H \times W\) and \(W \times H\) respectively, which are fed into two long short-term memory (LSTM) layers to capture semantic changes across spatial dimensions \(H\) and \(W\). The outputs from these LSTM layers are reshaped back to \(H \times W \times 1\) and concatenated to produce \(F_LSTM\). The SaB takes this \(F_LSTM\) as its input to generate \(F_symmetry\), by calculating pixel-wise feature similarity between \(F_LSTM\) and its transpose. This represents the symmetry-aware features. They first used a gradient-based fusion technique to fuse the features extracted by wavelet transform and soft attention and then concatenated it with the symmetry-aware features.

Overview of the soft attention unit proposed by Datta et al.130.
Observations: Attention mechanisms are indeed an effective way to detect skin cancer and contribute to improved classification performance. However, they come with potential disadvantages. One significant challenge is the increased computational complexity introduced by attention mechanisms, leading to higher resource requirements during both training and inference. Additionally, attention-based models may be more susceptible to overfitting, particularly when dealing with limited datasets. The intricate nature of attention mechanisms can result in capturing noise and anomalies as if they were specific patterns, potentially impacting the model’s performance on unseen data133.
While the approaches demonstrated in125,126 are innovative, attention mechanisms that assign weights to relevant lesion areas have been shown to yield better results. Although Xue et al.127 proposes a novel approach, the sequential application of channel and spatial attention mechanisms may cause one to overshadow the other. Combining the attention maps first and then applying them to the features would ensure a balanced and simultaneous influence on feature refinement. While Ding et al.128 produce effective results using their novel DABN model, they do not provide results for multi-class classification. Notably, Refs.130,131,132 demonstrate exceptional effectiveness but face challenges in classifying cancer types with fewer samples. To address this issue, one possible mitigation approach can involve employing a combination of transfer learning with few-shot learning or zero-shot learning. Another potential solution can involve generating synthetic samples of the underrepresented classes using GAN-based models, providing a more sophisticated alternative to simple data augmentation techniques. Also, the combination of wavelet transform, soft attention, and SaFA module, in132, can be computationally intensive. Moreover, although attention mechanisms offer a degree of interpretability by emphasizing crucial parts of the input images, the specific interpretation of attention weights can sometimes be confusing. Comprehending the exact reasoning behind the model’s attention-based decisions may pose challenges.
Ensemble-based techniques
Ensemble techniques within DL consolidate predictions from multiple individual base models to generate more reliable predictions. By aggregating the knowledge from diverse models, ensemble methods commonly showcase enhanced adaptability to new data by diminishing errors in bias and variance. In the context of skin cancer, where lesion appearance can vary widely, ensemble techniques enable the system to recognize a broader range of features associated with different types of skin lesions. A comprehensive study of different methods for skin cancer classification using ensemble techniques is provided in Table 9. To facilitate a better generalization for the readers, we have adopted a broader interpretation of ensemble techniques, encompassing any combination of models, including strategies such as feature concatenation, fusion, and stacking, in addition to traditional ensemble approaches.
Harangi et al.’s study134 involved using various deep CNN architectures like AlexNet, VGGNet, and GoogLeNet. The final prediction was determined through a weighted majority vote, with each CNN’s vote being weighted by its confidence as indicated by the softmax output. Shahin et al.135 utilized two pre-trained deep CNN architectures, ResNet50 and InceptionV3, as distinct models in their ensemble. Instead of simply averaging the predictions from these individual models, the features extracted from both CNNs were concatenated and passed through a fully connected layer. Subsequently, the output of the fully connected layer was directed to a final layer equipped with a softmax activation function. Serte et al.136 introduced a Gabor wavelet137 based deep CNN. The approach involved decomposing input images into seven directional sub-bands. These seven sub-band images, in conjunction with the input image, acted as inputs for eight parallel CNNs, producing eight probabilistic predictions. The classification of skin lesions was accomplished through decision fusion using the sum rule. The Gabor-based strategy facilitated directional decomposition, allowing each sub-band to contribute isolated decisions that could be fused to enhance overall performance.
Aldwgeri et al.138 proposed an ensemble approach using multiple pre-trained CNN architectures like VGG16, ResNet50, InceptionV3, Xception, and DenseNet121. The predicted probabilities of each CNN for 7 different types of skin lesions were weighted and averaged to generate the final ensemble prediction. El-Katib et al.139 leveraged three pre-trained CNNs, GoogLeNet, ResNet101, and NasNetLarge for skin cancer classification. They combined the results from all the individual models into a global decision system based on a weighted approach, where each model’s weight was determined according to their individual accuracies. Bajwa et al.140 employed four deep CNN architectures, ResNet152, DenseNet161, SEResNeXt101 and NASNet to capture features from the skin lesion images focusing on aspects like color, texture, and borders. Predictions from the individual deep CNNs were not simply averaged. Instead, an ensemble learning approach was used to boost the accuracy and robustness of the model.
Gessert et al.141 utilized an ensemble of EfficientNet models for the classification of skin cancer on the imbalanced ISIC 2019 dataset. To address the challenge of class imbalance, they employed a loss balancing approach. This involved implementing a weighted cross-entropy loss function, where the weights assigned to classes were determined by their frequency in the training set. Imran et al.142 used an ensemble of three separate models, VGGNet, ResNet, and CapsNet. Here, predictions from each model were combined using majority voting, where the most frequent prediction becomes the final output. Hasan et al.143 introduced a hybrid CNN model comprising three distinct feature extractor modules, which are integrated to enhance the depth of feature maps for skin lesions. The fused feature maps undergo classification using separate fully connected layers, and their predictions are then ensembled to determine the lesion class. In the model’s architecture, FMG-1, FMG-2, and FMG-3 represent the three feature map generator modules. In the first level of ensembling, feature fusion is conducted through both channel averaging and channel concatenation. Ultimately, the output probability is determined by averaging the outputs of the fully connected layers, referred to as second level ensembling.
Ichim et al.144 examined two ensemble models. The first model consisted of three neural networks, MobileNet, DenseNet121, and DenseNet169, with an ensemble of individual decisions determined by the weights associated with each individual network. The second model incorporated two networks, MobileNet and DenseNet169, and followed a horizontal voting approach, where the ensembling was determined by the voting from the best models associated with the considered number of epochs. The second ensemble strategy was observed to deliver superior results compared to the first. Sarkar and Ray145 employed three deep CNN architectures, ResNet50, InceptionResNetV2, and DenseNet201, each of which was aided with an attention module. Subsequently, their prediction scores were combined using a novel classifier combination method based on Dempster–Shafer theory146. Ayesha et al.147 employed three pre-trained CNN models, VGG16, VGG19, and ResNet50, as feature extractors. The extracted features were concatenated into a composite feature vector, which was subsequently passed through a final dense layer for classification. Mandal et al.148 introduced a unique feature fusion method, combining the outcomes of two deep learning models. Their approach utilized Xception and Google’s Big Transfer (BiT-M) model as base learners, complemented by a squeeze and excitation attention module149 to improve the fused feature maps. This feature fusion network achieved an impressive accuracy of 79.50% on the challenging ISIC 2017 dataset.
Gairola et al.150 developed a deep network that leverages feature fusion to enhance skin cancer classification performance. The network features two main components: an improved single block (ISB) and an improved fusion block (IFB). The ISB increases the efficiency of a single CNN by enlarging the skin lesion feature map using zero padding, a convolutional layer, and ReLU activation. The IFB enhances the network’s capability by capturing extensive contextual information and global features through multi-dimensional exploration. They applied the ISB to enhance ResNet50 and ResNet101V2 architectures, combined their outputs, and utilized the IFB for the fusion and classification task. Naeem et al.151 employed borderline synthetic minority oversampling technique (SMOTE) to address class imbalance in skin cancer datasets. For feature extraction, they utilized both the Xception and ResNet101 models. The extracted features were then concatenated and passed through an additional convolutional layer. Afterwards, the feature map was flattened and used for classification to predict the skin cancer types.
Observations: Ensemble methods involve training multiple models, and various strategies can be employed to combine their prediction scores, creating robust models without the need to repeatedly train individual base learners. However, this approach may introduce increased computational constraints and resource requirements as the number of base learners grows, potentially impacting deployment on real-time applications. Moreover, building and managing an ensemble also demands careful consideration of model selection, training, and integration, adding complexity and time consumption to the process.
Although Refs.134,136,138,139,140,142,144 produce impressive results, they employ simple majority voting, sum rule or weighted average based algorithms to combine the predictions from base learners. The implementation of more sophisticated combination algorithms for handling uncertain classes could potentially improve predictions. Additionally, in136, the Gabor wavelets employ parameters such as frequency and orientation that require meticulous tuning to achieve optimal performance. Gessert et al.141 introduces an innovative load balancing approach to address the class imbalance issue. Nonetheless, an enhanced ensembling strategy can further improve overall performance. References135,143,148,150 leverage the feature fusion strategy to produce enhanced feature maps with discriminative information, resulting in impressive test results. Optimizing feature selection before passing feature maps to the classification layer may further enhance performance. Sarkar et al.145 boasts remarkable results on the challenging HAM1000 dataset. However, the Dempster–Shafer theory-based combination introduces computational intensity, with complexity scaling up as the number of base learners increases. Ayesha et al.147 achieved promising results on the ISIC dataset; but, the authors did not evaluate their model on additional datasets, leaving its generalizability untested. Naeem and Anees151 demonstrates impressive results; however, the use of a proprietary dataset limits the ability to directly compare their findings with other studies.
Generative adversarial network-based techniques
The main utility of a GAN-based model lies in its capacity to generate synthetic samples that closely resemble real ones, preserving the same underlying data distribution152. Although GANs are not conventionally used directly for classification tasks such as skin cancer classification, they can indirectly contribute by addressing the imbalanced skin cancer datasets. GANs have the potential to generate synthetic images for underrepresented classes, thereby alleviating class imbalances and augmenting the dataset153. Table 10 presents a comprehensive overview of GAN-based techniques applied to skin cancer classification, detailing the diagnosed skin cancer types, datasets used and the achieved results.
Rashid et al.154 introduced a skin lesion classification system based on GANs. In their approach, they performed data augmentation on a training set of images by incorporating synthetic skin lesion images generated using a GAN. The generator module in their system employed a deconvolutional network, while the discriminator module used a CNN as the classifier. The CNN was trained to classify skin lesions into seven different categories. The proposed GAN-based approach outperformed both ResNet50 and DenseNet, achieving an accuracy of 86.10% for skin lesion classification. Bisla et al.155 introduced an approach that combines DL for data refinement and GANs for data augmentation. In their proposed framework, the initial step involved data purification using conventional image processing methods, followed by lesion segmentation utilizing a U-Net architecture. Subsequently, they employed decoupled deep convolutional GANs (DCGANs) to generate additional data. This refined and augmented dataset was then used to fine-tune a pre-trained ResNet50 model for the classification task, categorizing dermoscopic images into 3 types. Figure 9a,b depict the block diagram of this system and the architecture of the DCGAN model, respectively.
Chen et al.156 proposed a novel data augmentation approach for skin lesions employing a Self-Attention Progressive Generative Adversarial Network (PGAN) in their study. They employed stabilization techniques to enhance this generative model, resulting in an accuracy of 70.10%. Cheng et al.208 introduced a GAN architecture featuring multiple convolutional layers and upsampling in the generator module. Their discriminator module consisted of a CNN and a gradient penalty function, aimed at improving image quality and preventing artifacts.

(a) Block diagram of the GAN-based model proposed by Bisla et al.155; (b) Architecture of the DCGAN proposed by Bisla et al.155.
Observations: GAN-based models focus on creating synthetic data that mirrors the characteristics of a specified dataset. This principle holds significant promise in medical imaging, particularly in addressing the prevalent issue of limited data availability. However, in the context of skin cancer classification, the usefulness of GANs can be limited, as they often fail to address several domain-specific challenges. Skin lesions vary widely in size, shape, color, and texture, making it challenging for GANs to capture the subtle differences between benign and malignant lesions. These models often struggle with generating fine-grained details, such as irregular borders, asymmetry, and pigmentation variations, which are crucial for accurate diagnosis. GAN-generated images may appear blurry or overly smooth and lack the diagnostic precision needed. Additionally, the synthetic images might exhibit limited diversity and struggle to generalize effectively to new data, potentially causing overfitting. The training process for GANs can be computationally demanding and time-consuming, posing further challenges for their practical implementation in real-time clinical applications.
The outcomes of Refs.154,156,208 appear unsatisfactory, indicating the necessity for greater emphasis on enhancing the generator module’s effectiveness. Bisla et al.155 yields impressive results despite being a heavy network. They employed two separate DCGAN models to generate synthetic images for the underrepresented classes of melanoma and seborrheic keratosis in the ISIC 2017 dataset. Exploring the application of conditional deep convolutional GANs can help reduce computational constraints157.
Vision transformer-based techniques
ViTs have shown immense promise in various medical image analysis tasks, including skin cancer classification158. Their role in skin cancer classification involves leveraging their ability to learn representations from images broken down into patches and capture intricate patterns and features that distinguish among different types of skin lesions. Moreover, ViTs provide attention maps, highlighting areas, where the model focuses its attention159. In skin cancer classification, this can aid dermatologists in understanding which regions or features the model uses to make its predictions, contributing to interpretability. Table 11 provides a comprehensive list of ViT-based skin cancer classification techniques, highlighting the diagnosed skin cancer type, dataset, and the obtained results.
Aladhadh et al.160 designed a two-tier framework to classify skin cancer. In the first stage, they applied various data augmentation techniques to tackle class imbalance in the HAM10000 dataset. In the second stage, they employed a medical ViT, where the lesion images of size \(72 \times 72\) were fed as input and each image was split into nine patches. Their transformer comprised three layers: an embedding layer, an encoder layer and a classifier layer. In the embedding layer, the transformer processed each patch as an individual token and then mapped it to a specific dimension with a learnable linear projection. The encoder layer contained self-attention and concatenation layers. The classifier layer predicted the final classification decision. Arshed et al.161, in their study, compared a fine-tuned ViT with various pre-trained CNN models of the ResNet, DenseNet and VGG families. According to their experiments, the ViT model outperformed all the other TL-based CNN models with an accuracy of 92.14%.
A four-block approach was proposed by Yang et al.162.It refers to the four-block architecture devised by their team. In the first block, seven different classes of cancer were balanced using various data augmentation methods. The image restructuring block formed the second block, which was responsible for splitting a 2D input image into a sequence of patches of the same size. These patches underwent flattening into tokens with consistent dimensions, followed by positional embedding to retain spatial information. The resulting output served as the input for the subsequent transformer encoder block. The third block comprised the transformer encoder block, featuring N repeated layers. Each layer contained a multi-head self-attention layer and a fully connected feed-forward network. The features derived from this encoder were employed for cancer classification in the final classification block. This block included a flatten layer, two normalization layers, a dense layer, and a softmax layer. This approach demonstrated promising results, surpassing other attention-based methods with an impressive classification accuracy of 94.10%. Krishna et al.163 leveraged ViT-based GANs (ViTGANs) to generate synthetic images as a solution to address the issue of class imbalance. Subsequently, they utilized a ViT consisting of identical layers of multi-head self-attention blocks and multi-layer perceptron (MLP) blocks to extract image features. These extracted features were then forwarded to a classifier for the estimation of class labels.
Observations: ViTs, due to their built-in self-attention mechanisms, are experts in capturing global relationships among different parts of an image without the constraint of localized receptive fields. However, they are computationally intensive and consume high memory, especially as the image resolution increases. Since ViTs rely on understanding relationships between image patches, they benefit from large and varied datasets and may not generalize well if the images are limited or lack diversity. Moreover, ViTs process images in a sequence of non-overlapping patches, potentially losing detailed spatial information, crucial for precise lesion analysis164.
References160,161,162,163 demonstrate impressive results underscoring the efficiency of ViTs. Moreover, Yang et al.162 retains the spatial information by injecting additional positional embeddings into the tokens, allowing the model to learn and distinguish the position of tokens in the sequence. However, Krishna et al.163 demands substantial computational resources since they employ ViTGANs for image generation as well as ViTs for classification. Also, neither of these papers test their method on smaller datasets to validate the results.
Segmentation-guided classification techniques
In the context of skin cancer classification, segmentation-guided classification techniques serve to be extremely powerful. It helps isolate the lesion from the surrounding skin and other artifacts in the image. This reduction in noise and background interference leads to a cleaner input for the classification model, potentially improving its performance. These techniques enhance the extraction of features specifically from the identified ROI. This results in a more precise representation of the skin lesion, allowing the classification model to focus solely on relevant information. Table 12 provides a comprehensive list of various segmentation-guided skin cancer classification techniques.
Yu et al.165 introduced a two-stage framework for melanoma detection. The first stage involved lesion segmentation, where a fully convolutional residual network (FCRN) with 16 residual blocks was employed to accurately delineate the skin lesion from the surrounding healthy skin. This ensured that the subsequent classification focused specifically on the relevant region. In the second stage, a distinct ResNet architecture was utilized to classify the segmented lesion as either melanoma or non-melanoma. The melanoma classification achieved an accuracy of 85.50% with segmentation and 82.80% without segmentation on the ISIC 2016 dataset. The framework proposed by Al-masni et al.166 integrated two key stages: a skin lesion boundary segmentation stage and a multiple skin lesion classification stage. Initially, skin lesion boundaries were segmented from dermoscopy images using a full resolution convolutional network (FrCN). Subsequently, various deep CNNs, including Inceptionv3, ResNet50, InceptionResNetv2, and DenseNet201, were employed for the classification of the segmented skin lesions. The first stage, accomplished by FrCN, was crucial as it extracted prominent features essential for diagnosing various types of skin lesions. The selection of a promising classifier was determined through thorough testing of various CNNs.
Hasan et al.167 proposed the Dermo-DOCTOR system, utilizing end-to-end dual encoders for both segmentation and classification tasks. The model incorporated two distinct encoders, each specialized in extracting different features from input images. Encoder 1 focused on global features, capturing the overall structure and shape of the lesion, while encoder 2 concentrated on local features, extracting fine-grained details within the lesion. These encoders were seamlessly integrated into a single, end-to-end trainable architecture, enabling simultaneous detection and recognition. The features extracted from both encoders were fused and directed into two separate branches: the detection branch, responsible for localizing the precise boundaries of the lesion within the image, and the recognition branch, which classified the lesion into different categories. Gerges et al.168 employed a segmentation strategy, utilizing the k-means clustering algorithm, with a k-value of 2, for ROI extraction. The resultant segmented images were then passed as input to a CNN consisting of 2 convolutional layers, each succeeded by a pooling layer, and concluded with 2 fully connected output layers.
Sai Charan et al.169 employed a two-path CNN model, incorporating two separate deep CNNs. One CNN received original images as input, while the other received images segmented using the U-Net architecture. Deep features from both CNNs were combined and utilized by the dense layers for the classification process. Gururaj et al.170 employed an encoder-decoder architecture for image segmentation, incorporating convolutions and max pooling in the encoder, and upsampling along with convolutions in the decoder. The encoder’s role was to identify and capture pertinent patterns, textures, and structures within skin lesions, with deeper layers gradually learning more intricate representations. Meanwhile, the decoder played a critical role in precisely localizing and delineating lesion boundaries, refining the features extracted by the encoder and generating a detailed and pixel-wise segmentation map. For the classification task, the study utilized two deep CNNs, namely DenseNet169 and ResNet50. In this task, DenseNet169 outperformed ResNet50, achieving an impressive accuracy of 91.20% on the HAM10000 dataset.
Khan et al.171 proposed a framework consisting of two main blocks: one for segmentation and localization and another for classification. For the lesion segmentation task, they employed two separate CNNs. The original images were fed into one CNN, while contrast-enhanced images were fed into the other. The outputs from these CNNs were then fused using the joint probability distribution and marginal distribution function to create a refined segmented image. This refined image was subsequently used as input for a 30-layer CNN architecture, which included 2 fully connected layers. Features extracted from these layers were combined using summation discriminant correlation analysis. To prevent feature redundancy, the regula falsi method was utilized for dimensionality reduction. Finally, the selected features were classified using an ELM classifier.
Similar to the approach of Gerges et al.168, Naeem et al.172 applied the k-means clustering algorithm with two clusters to segment the ROI from lesion images. Their methodology first employed anisotropic diffusion to denoise the images, followed by the application of SMOTE-Tomek to address the class imbalance problem in the ISIC 2019 dataset. After pre-processing, segmentation was performed, and feature extraction was conducted using both VGG19 and HOG. The extracted features were then serially fused, and maximum entropy-based feature selection was applied to retain the most informative features. Finally, the selected feature vector was fed into a classification head to generate predictions for skin cancer classification.
Observations: Segmentation provides information about the spatial extent and boundaries of the skin lesions. This can be valuable for especially understanding the localized characteristics of the skin condition, aiding in more accurate classification. While segmentation-guided classification techniques are immensely promising, they also come with certain limitations. The need for precise segmentation may lead to increased resource requirements, making the techniques computationally intensive. Additionally, errors in the segmentation process can propagate into the subsequent classification stage, affecting the overall accuracy of the system.
While Refs.165,166,167,169,170,171 demonstrate impressive results, the utilization of separate networks for segmentation and classification introduces increased model complexity, making training and optimization more challenging. Additionally, comprehending the contributions of features from each encoder in167 and their impact on final decisions may pose challenges. The FrCN block presented in166, is adept at pixel-wise classification and can generate precise segmentation masks. However, its computational cost is high, primarily attributed to pixel-level computations. The framework described in171 relies on image quality, including contrast enhancement. As a result, it may be sensitive to variations in image acquisition conditions, such as differences in lighting and resolution. References168,172 utilize a rather simple and computationally efficient segmentation strategy based on the k-means clustering algorithm. However, they do not provide an explicit justification for choosing a k-value of 2. Furthermore, the reliance of Gerges and Shih168 on the small MED-NODE dataset for testing prompts inquiries about the model’s generalizability to larger datasets. Although Naeem and Anees172 demonstrates impressive performance on the ISIC 2019 dataset, their model’s dependence on manually designed feature extraction methods may limit its adaptability in real-world settings, especially when compared to fully end-to-end DL approaches.
Hybrid techniques
The combination of DL and ML techniques (hybrid approaches) holds significant importance for image classification tasks. DL methods, especially pre-trained CNN models, excel in feature extraction from images. When coupled with traditional ML algorithms like SVM or RF, these hybrid models can leverage the strengths of both approaches, potentially leading to improved classification accuracy. Moreover, DL models often demand abundant labelled data for training. Hybrid strategies can alleviate this requirement by leveraging pre-trained DL models for feature extraction, followed by employing ML techniques on these extracted features173. In the realm of skin cancer classification, these hybrid techniques prove highly beneficial. DL models are adept at learning hierarchical representations from raw data, which can be beneficial for capturing intricate patterns from skin lesion images. By integrating ML algorithms, the hybrid models can utilize these patterns as input features, facilitating accurate classification, even in scenarios of limited data, a common challenge in skin cancer applications. Additionally, combining features extracted by DL models with handcrafted features can enhance the robustness of the classification process. This approach leverages the complementary strengths of both feature types; while DL models capture complex patterns, handcrafted features can provide contextual or domain-specific insights that may improve classification performance. By incorporating both types of features, hybrid models can create a more comprehensive representation of the data, ultimately leading to improved diagnostic accuracy and reliability in clinical settings. A comprehensive list of various skin cancer classification systems based on hybrid techniques is listed in Table 13.
Shoieb et al.174 developed a standard CNN for feature extraction. The CNN consisted of convolution, pooling, non-linear and fully connected layers. Initially, the first convolutional layer was dedicated to capturing rudimentary features such as edges and corners, while subsequent convolutional layers focused on extracting more intricate patterns. The pooling layers condensed the representations of these features. The extracted features were then trained on a linear SVM, which executed classification by determining the hyperplane that maximized the margin between the two classes (melanoma and non-melanoma). Dorj et al.175 employed a pre-trained AlexNet model for feature extraction from dermoscopic images and fine-tuned the final layers of the model. Then, they leveraged an error-correcting output codes (ECOC) SVM classifier176 for the classification task. ECOC method converts a problem of classifying among multiple classes into a series of two-class classification problems (one-vs-all approach).
Khan et al.177 utilized pre-trained ResNet50 and ResNet101 to extract diverse features from the dermoscopic lesion images, focusing on textures and borders. These extracted features from both the deep CNNs were fused to create a comprehensive lesion representation. Then, they employed the kurtosis controlled PCA (KcPCA)178 method to select discriminative features based on high kurtosis from the fused representation. Finally, an SVM with an RBF kernel was used to classify the selected features into distinct skin lesion categories. This work aimed to enhance classification accuracy by leveraging distinct feature extraction, fusion, selection, and classification techniques. Mahbod et al.179 introduced a methodology for extracting deep features using pre-trained CNNs, including AlexNet, ResNet18, and VGG16, for skin lesion classification. These pre-trained networks served as deep-feature generators, and the extracted features were used to train a multi-class SVM classifier. The classification results from the SVM were then combined for the final classification.
Mahbod et al.180 also employed 3 sets of CNNs with different architectures. Set 1 consisted of two identical ResNet50 networks, set 2 consisted of two identical EfficientNetB0 networks, and set 3 consisted of two identical EfficientNetB1 networks. Each set of CNNs shared the same architecture, but different fine-tuning strategies were applied to each set. The CNNs within each set extracted features from the images, resulting in multiple sets of feature vectors. These feature vectors were concatenated to create a comprehensive feature representation for each image. The fused feature vectors were then input into different SVMs, each trained for a specific lesion category. This approach allowed for separate classifiers targeting different lesions, potentially enhancing performance. Each SVM produced a class probability vector, and these vectors were averaged to generate the final ensemble prediction probabilities. Kassem et al.181 utilized GoogLeNet for feature extraction from the lesion images. They opted to remove only the last two layers, retaining the original fully connected layers within the GoogLeNet architecture for feature extraction. The extracted features were then employed in a multi-class SVM for classification.
Benyahia et al.182 employed 17 pre-trained CNN architectures as feature extractors to capture different aspects of the lesion like textures, borders, and color patterns. Subsequently, they utilized various ML classifiers to classify the lesion images. In their work, a combination of DenseNet201 and k-NN yielded the best results on the challenging ISIC 2019 dataset. 8 pre-trained CNN architectures, VGG16, VGG19, ResNet50, ResNet101, InceptionV3, DenseNet121, MobileNet, and Xception were used to extract deep features from dermoscopic lesion images by Gajera et al.183. They used SVM as a classifier to train the extracted features from all the deep CNNs, out of which DenseNet121 yielded the highest accuracy for melanoma detection.
Tembhurne et al.184 proposed a multi-branch approach by combining ML and DL techniques for skin lesion classification. In the DL branch, they employed a pre-trained VGG16 network to extract high-level features and perform image classification. In the ML branch, they leveraged the contourlet transform technique185 and LBPH to extract texture and color features from the image. These features were then concatenated, subjected to dimensionality reduction via PCA, and fed into two ML models-logistic regression and linear SVM. The final classification was determined by combining the outcomes from both branches through a voting mechanism, resulting in the categorization of images as malignant or benign. Figure 10 depicts the overview of this model. Keerthana et al.186 utilized a hybrid CNN architecture of DenseNet201 and MobileNet to capture both low-level features like textures and edges and high-level features like lesion patterns and shapes. Then, they applied PCA to reduce the dimensionality of the extracted features and improve computational efficiency. Finally, they leveraged an SVM classifier trained on the set of features with reduced dimensionality. Similar to the approach by Tembhurne et al.184, Naeem et al.187 also employed two branches that integrated both ML and DL techniques for feature extraction. In the ML branch, they utilized histograms for extracting color features, the GLCM for capturing global textural information, the features from accelerated segment test (FAST) and rotated binary robust independent elementary features (BRIEF) descriptors188 for local textural information, and Zernike moments189 to extract shape features. In the DL branch, they used the InceptionV3 model as the feature extractor. The features from both branches were then fused using an entropy-based fusion method, similar to the technique described in172, and the fused features were passed through the final dense layers for classification.
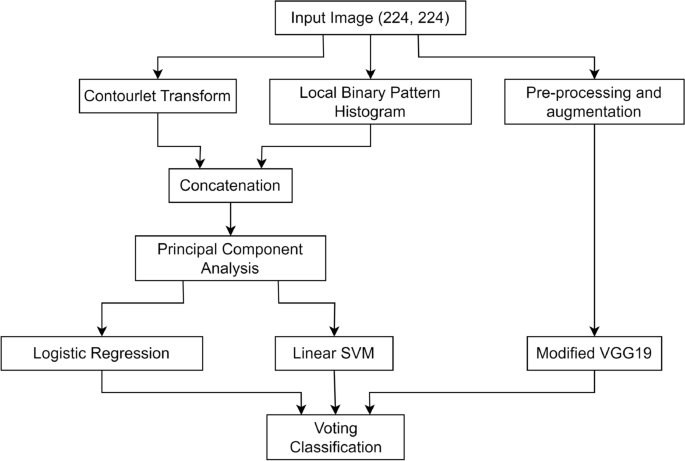
Overview of the hybrid model proposed by Tembhurne et al.184.
Observations: Hybrid approaches are beneficial since they eliminate the need for manual feature engineering, as they automatically learn relevant representations, spatial relationships and local structures from the data using DL models, reducing human bias and effort. Additionally, this approach proves advantageous, particularly in scenarios with limited labelled data, reducing computational demands without compromising performance. Furthermore, computational efficiency can be enhanced by reducing the dimensionality of features extracted by DL models before feeding them into ML classifiers. However, this reduction may result in the loss of crucial information. Therefore, maintaining a balance between dimensionality reduction and information preservation is vital. Consequently, optimal feature selection becomes imperative before inputting these extracted features into the ML classifier. This step aids in identifying the most relevant and discriminative features, improving classification performance and reducing the risk of overfitting.
The simple network by Shoieb et al.174 achieves fairly decent results on older datasets but its performance remains untested on newer, more complex datasets. Dorj et al.175 relies on a proprietary dataset for testing, limiting comparative studies with other models. References179,180 do not report overall accuracy scores making it difficult for comparison with other related methodologies. While the approach demonstrated in180 is robust, the use of separate SVMs for each class may not fully exploit potential correlations between classes. References177,183,184 showcase fairly decent results on challenging datasets. However, they do not perform multi-class classification, which could have been more relevant in real-world scenarios. Leveraging PCA to reduce the dimensionality of features, Keerthana et al.186 demonstrates computational efficiency without compromising classification accuracy. The extensive experiments performed by Benyahia et al.182 highlight the superiority of combining DenseNet201 and k-NN over using only DenseNet201. Similarly, in Kassem et al.181, the results indicate that a combination of GoogLeNet and SVM surpasses the performance of using only GoogLeNet. Naeem et al.187 highlights the significance of integrating both ML and DL techniques for feature extraction. However, the evaluation of their model is limited to a subset of the ISIC 2019 dataset, rather than the full dataset, which may restrict the comprehensiveness of their findings. These studies further validate the significance of using hybrid approaches in skin cancer classification.
Multimodal techniques
Multimodal techniques in skin cancer classification combine varied data streams, including images, clinical data, and pathology reports, providing a comprehensive and robust diagnostic solution. These approaches enhance generalization and improve diagnostic confidence by capturing multifaceted patterns. Integrating complementary information enhances interpretability, fostering a nuanced comprehension of skin lesions. A comprehensive study of different methods for skin cancer classification using such approaches is provided in Table 14.
Yap et al.190 introduced a multimodal fusion model which combined information from three modalities: macroscopic image, dermoscopic image, and patient metadata. The macroscopic images are analyzed by a CNN for spatial features and the dermoscopic images are analyzed by a different CNN for finer details. Patient metadata is encoded with a separate network using an embedding layer. The extracted features are fused and fed into a final neural network classifier to categorize the lesion images into malignant and benign. Ou et al.191 developed a DL model employing 2 encoders to extract information from image data and metadata. The image encoder utilized a deep CNN for feature extraction from the images, while the meta encoder processed textual metadata, including patients’ attributes and lesion characteristics, using an MLP. Subsequently, a multimodal fusion module with intra-modality self-attention and inter-modality cross-attention was employed to highlight crucial regions within each modality and capture interactions between image and metadata features respectively. The final classification layer predicted 6 distinct types of lesions.
Tajjour et al.192 introduced a multimodal network using an ensemble of CNN and MLP. They used a CNN to analyze the original RGB image to extract high-level features related to lesion shape, texture, and borders and used an MLP to process patients’ metadata and features, extracted from different color spaces, to capture additional information on color distribution, illumination, and energy within the lesion. These features were fused and classified using a final classification layer. The results revealed a top-1 accuracy of 86% and a top-2 accuracy of 95% for the seven classes. Omeroglu et al.193 introduced a multi-branch structure for multi-label skin lesion classification. They used two branches in their feature extraction phase, a dermoscopy branch and a clinical branch. A modified Xception architecture was used to extract visual features in the dermoscopy branch, whereas, they processed clinical data into numerical representations in the clinical branch. They also employed a soft attention module to analyze feature maps from both branches and assign weights based on their relevance to specific lesions. Subsequently, they designed a hyperbranched fusion block to combine weighted feature maps from different scales within each branch and across branches, creating a richer and more comprehensive representation of the lesion. Finally, they used a multi-label classification layer to compute output probabilities for each possible skin lesion label.
SM et al.194 employed EfficientNetB6 as the backbone of their model to extract features related to melanoma and non-melanoma lesions. They also designed a simple neural network to train the contextual information given in the ISIC 2020 dataset. The extracted features from both networks were concatenated and trained using a light gradient boosting machine (LGBM) classifier. In addition to this, they also utilized the Ranger optimizer195 to improve the model’s generalizability and overall performance. Kumar et al.196 introduced a multimodal network that utilizes handcrafted features derived from different domains of lesion images: spatial, frequency, and cepstrum. Initially, the RGB images are converted to grayscale. For the frequency domain, spectrograms are calculated, while for the cepstrum domain, cepstral coefficients are computed. The grayscale images, spectrograms, and cepstral coefficients are then transformed from 2-D to 1-D features. These features are concatenated and passed as input into a 1-D multi-headed CNN comprising three heads. The outputs from these heads are then concatenated for the classification task.
Sahoo et al.197 introduced an innovative multimodal framework for skin cancer classification by integrating deep features with wavelet features. They utilized a pre-trained ResNet50 model to extract deep features from lesion images. These images were then transformed into the wavelet domain using the lifting wavelet transform (LWT)198, specifically utilizing the level-2 approximation component as the wavelet features. The deep and wavelet features were combined and then subjected to the neighborhood component analysis (NCA) algorithm199 to select a reduced subset of the fused features. This reduced feature set was finally classified using an MLP.
Observations: While multimodal approaches enhance overall reliability and generalizability, such approaches introduce complexities due to potential challenges in aligning diverse data sources. Additionally, data collection for multiple modalities can be more resource-intensive and expensive.
Multimodal strategies demonstrated in190,191,192,193,194,196,197, offer new perspectives. However, Yap et al.190 falls short of achieving high performance, and Tajjour et al.192 does not report overall accuracy, limiting comparative analyses with other work. Ou et al.191 introduces an innovative multimodal fusion strategy but uses a self-procured dataset for testing instead of standard datasets. SM et al.194 demonstrates impressive results on the demanding ISIC 2020 dataset. Nevertheless, it falls short by not addressing multi-class classification, which could be more pertinent in real-world scenarios. Although Omeroglu et al.193 introduces a novel multi-branch structure, its multi-label classification approach limits direct comparisons with similar work. This method can be investigated further on more recent datasets for multi-class classification. Kumar et al.196 yields impressive results on challenging datasets but relies on manually engineered features from different domains of lesion images. They neither explicitly mention why they have specifically used the frequency and cepstrum domains, in addition to the spatial domain, nor how the features extracted from these domains could help boost classification performance. While Sahoo et al.197 demonstrates exceptional results on older datasets, it does not provide results on newer, more complex datasets.
link
")






